AAAI(Association for the Advancement of Artificial Intelligence)会议是人工智能领域的国际顶级学术会议,也是中国计算机学会(CCF)和中国人工智能学会(CAAI)推荐的A类国际学术会议。AAAI会议涵盖了人工智能领域的广泛议题,包括但不限于机器学习、自然语言处理、计算机视觉、强化学习、知识表示与推理、机器人学、自动化决策、伦理与社会影响等。经过同行专家两轮评审,蒙古文智能信息处理国家地方联合工程中心2篇论文被The 39th Annual AAAI Conference on Artificial Intelligence (AAAI 2025)录用。
SSAN: A Symbol Spatial-Aware Network for Handwritten Mathematical Expression Recognition
作者:张皓然,苏向东,周兴祥,高光来
单位:内蒙古大学
简介:手写数学公式识别(Handwritten Mathematical Expression Recognition, HMER)是一项将手写数学公式图像转换为下游应用可理解的LaTex序列的技术,在答卷评分、办公自动化以及文档理解等有广泛的应用前景。该任务的巨大挑战在于手写公式的复杂结构,而这种结构与符号的空间位置直接相关。现有的HMER方法通过解码器中的注意力机制隐式感知符号位置,或利用符号计数与基于树的策略建立符号空间关系模型,但仍难以有效捕捉公式结构信息,导致符号解码性能受限。
为了解决上述问题,本文提出了预测手写数学公式中符号空间分布图的辅助任务。设计了一个符号空间分布感知网络(SSAN),并与HMER模型进行了联合优化。具体来说,考虑到手写公式图像与其对应的印刷体模板之间符号空间位置分布的相似性,首先根据LaTeX标签生成手写公式图像的印刷体模板,然后用二维高斯分布图替换印刷体模板中的连通域分量,从而得到符号空间分布图。同时,由于手写公式图像和印刷公式图像之间的符号空间分布对齐不紧密,以及存在相似符号的误分类问题,又进一步提出了从粗到细的对齐策略和注意力引导的符号掩蔽策略来解决这些问题。大量实验证明,SSAN能显著提高HMER模型的识别性能,而且与现有的辅助任务相比,所提出的辅助任务能更有效地提高HEMR性能。
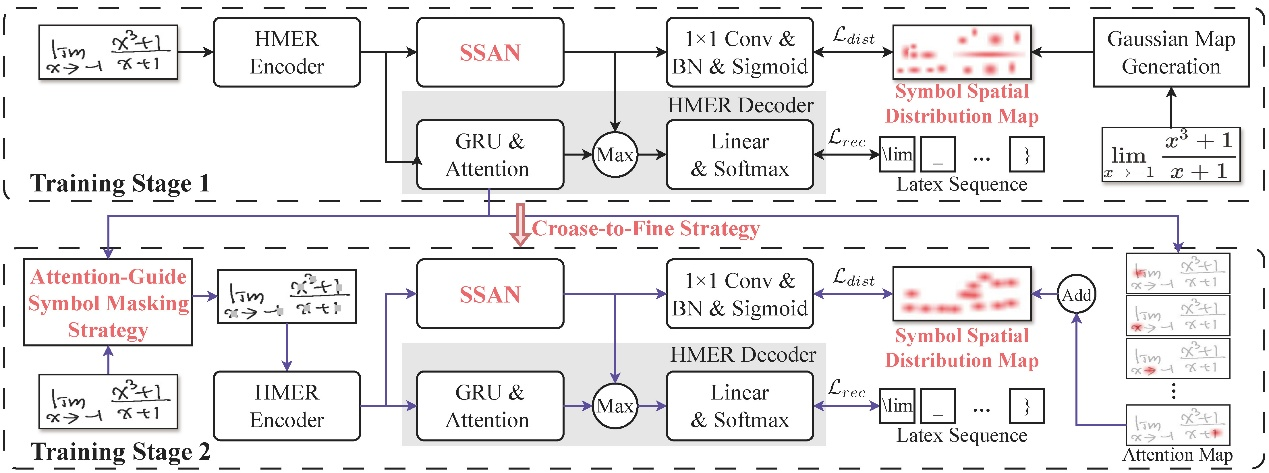
图1 SSAN与HMER模型联合训练的整体框架图
Multi-modal and Multi-scale Spatial Environment Understanding for Immersive Visual Text-to-Speech
作者:刘瑞,何树伟,胡一帆,李海洲
单位:内蒙古大学 香港中文大学(深圳)
简介:视觉文本到语音合成(Visual Text-to-Speech,VTTS)旨在利用环境图像作为提示,为说话内容合成与空间特性相匹配的混响语音。这一任务的主要难点在于如何准确理解图像中的空间环境信息。虽然目前已有不少研究尝试从图像的RGB空间中提取全局空间信息,但它们往往忽略了局部细节和深度信息这两个对空间环境理解至关重要的线索。为了解决这一问题,我们提出了一种名为M²SE-VTTS的全新多模态与多尺度空间环境理解框架,以实现沉浸式视觉文本到语音合成。多模态旨在融合空间图像的RGB和深度空间以学习更全面的空间信息,多尺度模块则致力于同时建模局部与全局的空间知识。具体而言,我们首先将RGB图像和深度图像划分为若干补丁块,并利用Gemini生成的环境描述来引导局部空间的理解。随后,我们通过局部感知的全局空间理解方式,将多模态与多尺度特征有机结合。这使得M²SE-VTTS能够在多模态空间环境中有效地处理局部和全局空间信息之间的关联。实验结果表明,无论是在客观指标还是主观评估中,我们的模型在环境语音生成任务上都显著优于当前主流的基线方法。
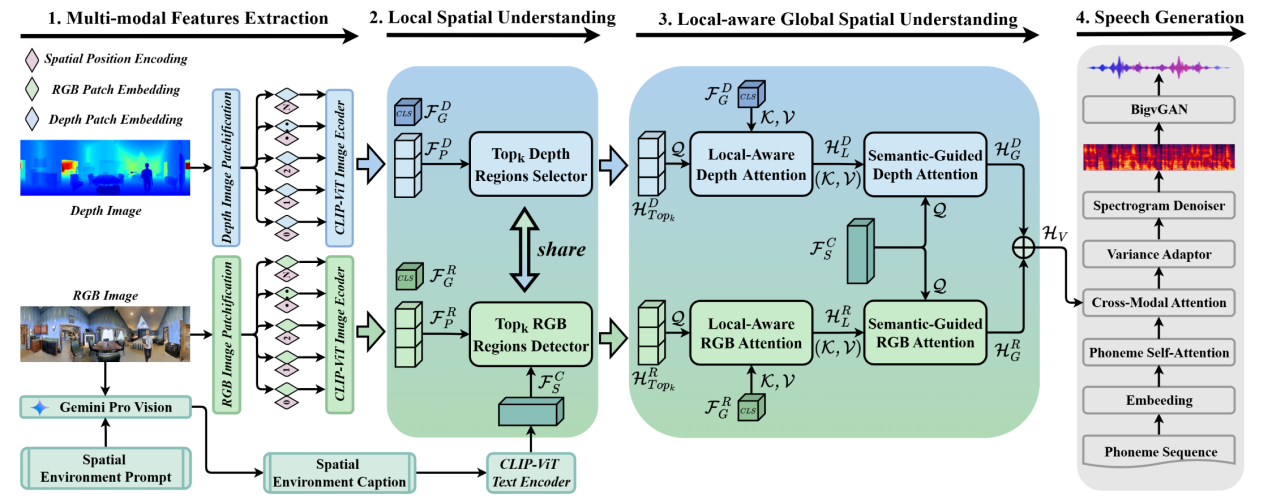
图2 M²SE-VTTS模型架构图
代码和音频样例可以通过以下链接获取:https://github.com/AI-S2-Lab/M2SE-VTTS。
